;)

How Enterprise Data Platforms Are Evolving Toward the Lakehouse
Many enterprise data platforms evolved by combining multiple specialized services. A common and successful pattern was to use Azure Data Factory (ADF) or Synapse Pipeline for orchestration, Azure Databricks for transformation, and Azure SQL Database to store metadata and configuration tables that controlled pipeline behavior. This approach worked well initially, especially when ingestion and control-flow logic were treated as separate concerns from transformation.
Over time, we built and operated a metadata-driven ETL platform using this model and deployed it across multiple customers at scale. The platform supported hundreds of datasets, with transformation-heavy workloads already running in Databricks, while orchestration logic and metadata interpretation lived outside the Lakehouse.
As Lakehouse platforms matured, we deliberately evolved our metadata platform and released a new Databricks-only version of the offering. We then applied this updated platform to some of the customers, and the results were immediately clear.
If data, compute, and governance already lived in Databricks, keeping orchestration and metadata control external no longer made architectural sense.
Why External Ochestration Conflicts with the Lakehouse Model
In the original architecture, ADF acted as the primary orchestration layer, while Azure SQL Database stored metadata tables. ADF pipelines handled looping, branching, watermark logic, triggers, and failure handling. Databricks notebooks focused on transformation and execution.
At a small scale, this separation was manageable. At a large scale, it introduced friction:
- Orchestration logic lived outside the Spark runtime
- Control-flow decisions were duplicated between ADF pipelines and Databricks notebooks
- Security, monitoring, and lineage were fragmented across services
- Pipeline complexity grew as the dataset count increased
This was not a failure of ADF. It was a structural mismatch. Once transformation-heavy workloads dominate, orchestration becomes tightly coupled to execution behavior, data layout, and runtime state, all of which already exist inside Databricks.
What Are the Benefits of Orchestration as a Native Lakehouse Capability?
When we redesigned our metadata platform as a Databricks-only offering, the motivation was driven by practicality and delivery.
The benefits of a Databricks-only offering include:
1. Cloud-Portable ETL (Avoid Azure Lock-In)
“We needed an ETL and orchestration solution that is not tightly coupled to a single cloud provider.”
ADF pipelines and Azure SQL–based control frameworks are inherently Azure-specific. By consolidating orchestration into Databricks Lakeflow Jobs within the Databricks Data Engineering platform, the execution model became largely cloud-agnostic.
The same pipelines, metadata tables, and notebooks now run consistently across Azure, AWS, and GCP, enabling lift-and-shift and multi-cloud strategies without requiring redesign of orchestration logic.
2. Cost Predictability & Reduction
“ADF costs grew unpredictably due to per-activity and orchestration charges.”
At scale, we observed that ADF costs were driven less by data volume and more by:
- Loop executions
- Number of activities
- Triggers
- Control-flow complexity
By moving orchestration into Databricks Lakeflow jobs, ADF orchestration charges were eliminated entirely.
3. Single Platform for Data, Security, and Governance
“Operating ADF for orchestration, Azure SQL for metadata, and Databricks for processing created fragmented security and monitoring.”
Before migration:
- Metadata security lived in Azure SQL
- Orchestration security lived in ADF
- Data access policies lived in Databricks
After consolidating our platform into Databricks:
- All configuration tables moved from Azure SQL into Unity Catalog
- Metadata, execution, lineage, and access control now live in one platform
- Governance policies are applied consistently at the data level
4. Transformation-First Architecture
“Most of our workload was transformation-heavy and already running in Databricks.”
The majority of business logic is joins, merges, CDC handling, and business rules already live in Databricks notebooks. Keeping orchestration in ADF added complexity without adding value.
By moving orchestration closer to the compute:
- Looping and conditional logic moved into notebooks
- Orchestration aligned directly with Spark execution behavior
- Failure recovery and restart logic became simpler and more reliable
Databricks does not charge based on the number of Jobs or Workflows. Costs are driven purely by compute runtime. As a result:
- Pipelines were consolidated
- Activity-based pricing disappeared
- Cost modeling became straightforward
- Optimization focused on Spark efficiency, not orchestration overhead
This resulted in measurable cost reduction and far greater predictability.
Metadata-Driven Pipelines as a Lakehouse Pattern
This migration did not eliminate metadata-driven design; it strengthened it.
Before
- Metadata tables stored in Azure SQL Database
- ADF pipelines queried metadata
- Databricks executed based on ADF decisions
After
- Metadata tables migrated to Unity Catalog Delta tables
- Databricks Jobs read metadata directly
- Utility notebooks manage: Configuration updates, Watermark progression, Operational state
- No pipeline code changes required when metadata changes
The key shift is that metadata interpretation moved into the Lakehouse, alongside execution.
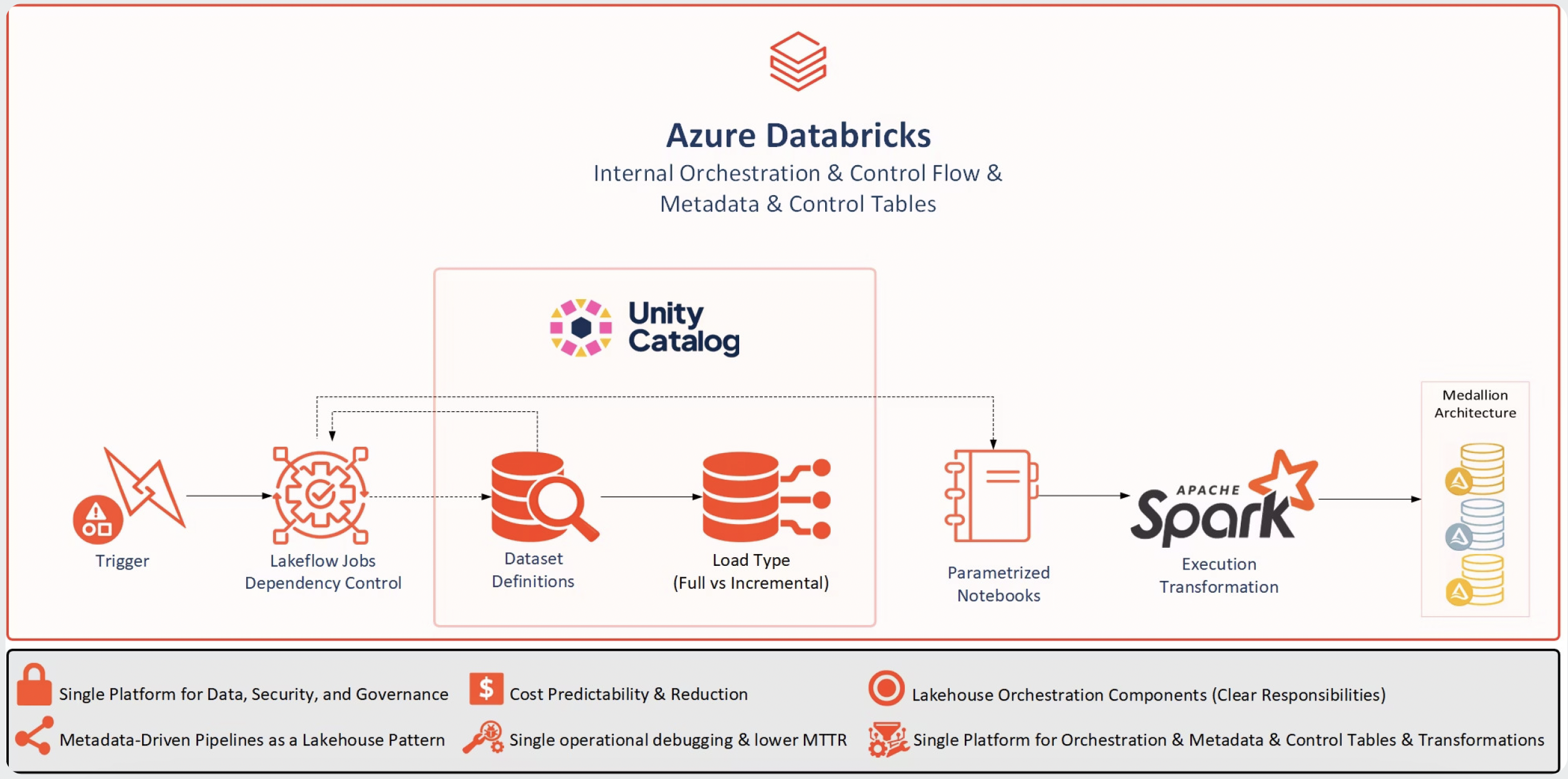
Lakehouse Orchestration Components (Clear Responsibilities)
After consolidation:
- Databricks Lakeflow Jobs handle scheduling, retries, entry points, dependencies, control flow and execution order, while using dynamic notebooks to run metadata-driven ingestion and transformation.
- Unity Catalog tables store configuration, metadata, and operational state
- Delta Lake provides consistent Bronze, Silver, and Gold storage
- Databricks Lakeflow Jobs provide a production-ready orchestration engine that is natively integrated into the Databricks platform and operates close to the data and AI workloads.
Each component does one thing well, without overlapping responsibilities.
Lakehouse Reference Architecture (Textual)
In the post-migration architecture:
- Metadata tables reside in Unity Catalog
- Jobs read metadata to determine execution behavior
- Generic notebooks dynamically ingest and transform data
- Bronze → Silver → Gold processing occurs entirely within Databricks
- Observability and logging are written back to Delta tables
This pattern is repeatable across domains and scales naturally.
Comparison Table: Lakehouse-Native vs External Orchestration
| Area | Before (ADF + Azure SQL + Databricks) | After (Databricks Only – Lakeflow) |
|---|---|---|
| Portability | Azure-centric | Multi-cloud capable |
| Orchestration | ADF pipelines | Databricks Jobs / Workflows |
| Metadata store | Azure SQL Database | Unity Catalog Delta tables |
| Metadata execution | Interpreted externally | Interpreted in Databricks |
| Control-flow logic | External | Inside Databricks |
| Pipeline complexity | High | Significantly reduced |
| Cost model | Per activity | Compute-based |
| Governance | Fragmented | Unified |
Where ADF Still Fits in a Lakehouse World
ADF continues to have value for:
- Lightweight ingestion
- SaaS connectivity
- Transitional architectures
For our updated metadata platform, however, it is no longer the core orchestration engine.
Practical Lakehouse Best Practices
Lessons reinforced by applying this new platform to customers:
- Design for restartability and idempotency
- Keep orchestration thin
- Centralize metadata in Unity Catalog
- Prefer dynamic, reusable notebooks
- Treat Jobs as the control plane
- Design for restartability and idempotency
Conclusion: Orchestration Is Part of the Lakehouse
This evolution was not about replacing ADF; It was about maturing our metadata platform.
Once orchestration, metadata, execution, governance, and observability converged inside Databricks, the platform became simpler to operate, easier to scale, and cheaper to run.
In mature Lakehouse platforms, orchestration is no longer an external integration layer; It is part of the data platform itself.
Architectural Simplification: From Split Control Planes to a Unified Lakehouse
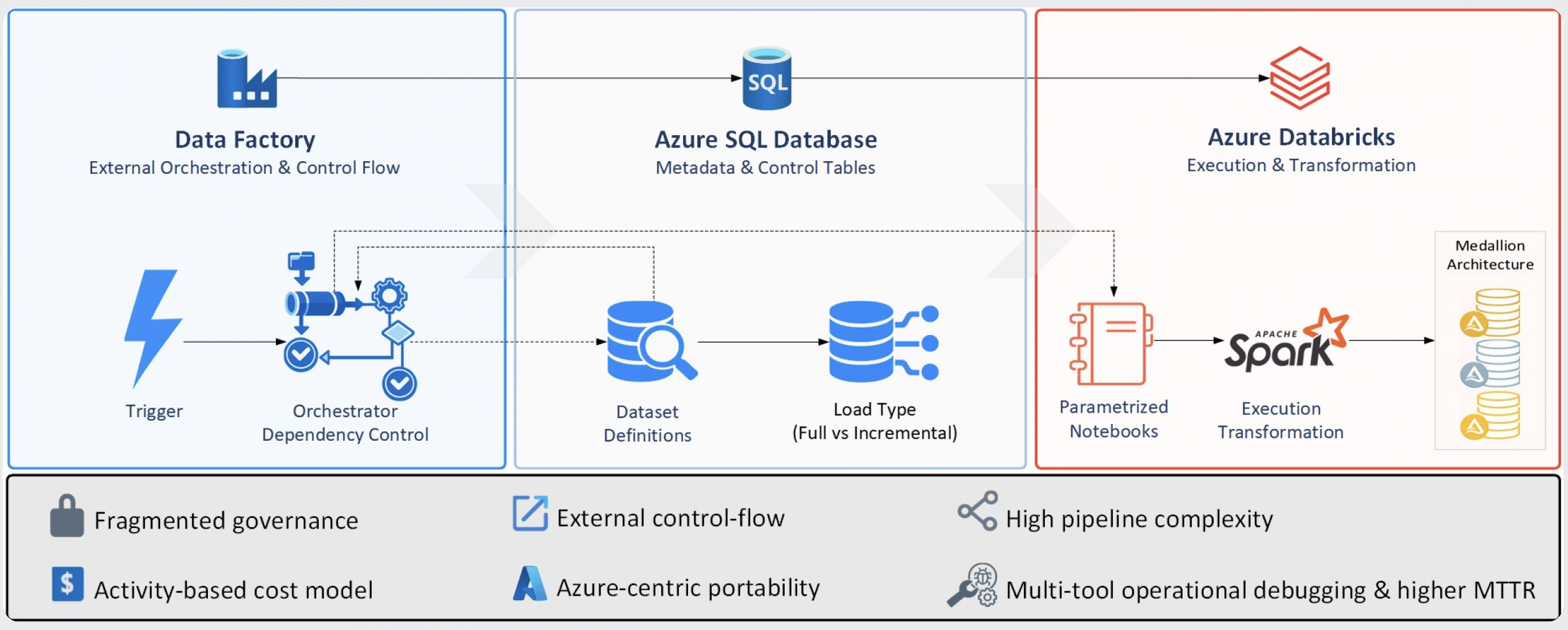
The diagrams below illustrate how the platform architecture evolved as orchestration and metadata management were consolidated into the Lakehouse.
Before Migration to Lakehouse
This diagram summarizes the original platform design, where orchestration, metadata, and execution were intentionally separated across Azure Data Factory, Azure SQL Database, and Azure Databricks. This layout provides context for how control flow and metadata management evolved before consolidation.
After Migration to Lakehouse
This diagram shows the simplified target state, where orchestration, metadata, and execution are handled natively within Azure Databricks. This view highlights the architectural shift toward a unified Lakehouse model.